버섯분류 데이터 셋
버섯분류 데이터 셋¶
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('https://raw.githubusercontent.com/Datamanim/mushroom/main/mushpre.csv')
Question 1
데이터를 df변수에 입력받고 각 열의 중복되지않는 원소의 수로 구성된 데이터 프레임을 형성하라. uniqueDf 변수에 저장하고 개수에 따른 내림차순 정렬 후 상위 3개 데이터를 출력하라
df.head(3)
| class | cap-shape | cap-surface | cap-color | gill-attachment | stalk-color-above-ring | stalk-color-below-ring | veil-type | veil-color | ring-number | habitat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | p | x | s | n | f | w | w | p | w | o | u |
| 1 | e | x | s | y | f | w | w | p | w | o | g |
| 2 | e | b | s | w | f | w | w | p | w | o | m |
uniqueDf.head(3)
| className | Counts | |
|---|---|---|
| 3 | cap-color | 10 |
| 5 | stalk-color-above-ring | 9 |
| 6 | stalk-color-below-ring | 9 |
Question 2
종속변수를 y (class)와 독립변수를 x 의 변수에 저장하여라. 변수타입 중 ‘veil-color’는 value 값이 1가지밖에 없으므로 제거하고 사용한다
y.head(3)
0 0
1 1
2 1
Name: class, dtype: int64
x.head(3)
| cap-shape | cap-surface | cap-color | gill-attachment | stalk-color-above-ring | stalk-color-below-ring | veil-color | ring-number | habitat | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | x | s | n | f | w | w | w | o | u |
| 1 | x | s | y | f | w | w | w | o | g |
| 2 | b | s | w | f | w | w | w | o | m |
Question 2
독립변수 x를 LabelEncode하여 x_label변수에 저장하라
x_label.head(3)
| cap-shape | cap-surface | cap-color | gill-attachment | stalk-color-above-ring | stalk-color-below-ring | veil-color | ring-number | habitat | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 5 | 2 | 4 | 1 | 7 | 7 | 2 | 1 | 5 |
| 1 | 5 | 2 | 9 | 1 | 7 | 7 | 2 | 1 | 1 |
| 2 | 0 | 2 | 8 | 1 | 7 | 7 | 2 | 1 | 3 |
Question 3
훈련 데이터셋과 테스트 데이터를 7:3으로 나누고 층화추출하여라
X_train.shape ,X_test.shape ,y_train.shape ,y_test.shape
((5686, 9), (2438, 9), (5686,), (2438,))
y_train.value_counts()
1 2945
0 2741
Name: class, dtype: int64
Question 4
SMOTE 방식을 이용하여 훈련 데이터의 부족한 종속변수 class를 over sampling 하라
y_train_over.value_counts()
0 2945
1 2945
Name: class, dtype: int64
Question 5
랜덤포레스트 방식을 이용하여 분류모델을 만들고 학습하라. 모델평가를 테스트셋으로 진행하고 accuracy, precision, recall 값을 구하여라
print(report)
precision recall f1-score support
class 0 0.82 0.61 0.70 1175
class 1 0.71 0.88 0.78 1263
accuracy 0.75 2438
macro avg 0.77 0.74 0.74 2438
weighted avg 0.76 0.75 0.74 2438
Question 6
테스트셋에 대해 ROC커브를 그리고 auc 값을 측정하라
plt.show()
print('base line: ROC AUC=%.3f' % (ns_auc))
print('pred: ROC AUC=%.3f' % (lr_auc))
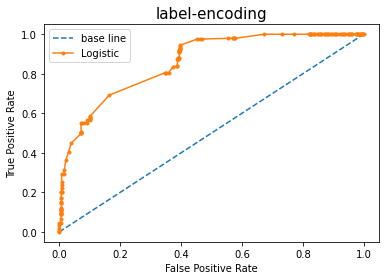
base line: ROC AUC=0.500
pred: ROC AUC=0.860
Question 7
학습한 모델의 변수 중요도를 아래의 그래프 처럼 출력하라
plt.show()
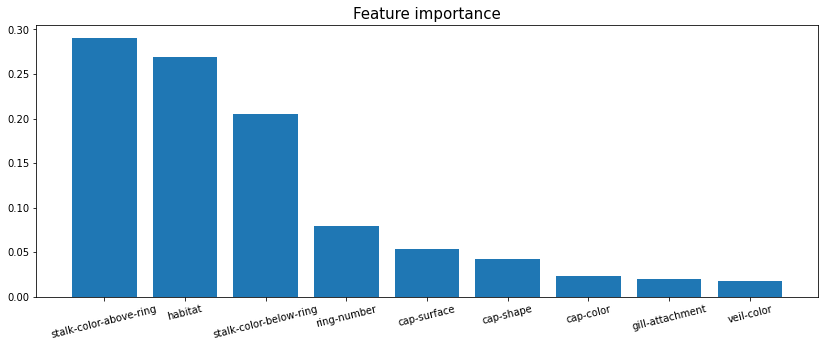
Question 8
독립변수를 Label encoding 방식이 아닌 one-hot encoding 방식으로 데이터를 변환 하여 x_dum 변수에 저장하라
x_dum.head(3)
| cap-shape_b | cap-shape_c | cap-shape_f | cap-shape_k | cap-shape_s | cap-shape_x | cap-surface_f | cap-surface_g | cap-surface_s | cap-surface_y | ... | ring-number_n | ring-number_o | ring-number_t | habitat_d | habitat_g | habitat_l | habitat_m | habitat_p | habitat_u | habitat_w | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
3 rows × 54 columns
Question 9
위의 학습 과정을 반복한다. 기존에 사용한 random_state값은 고정한다 smote 층화추출, randomforest 학습, 모델 평가 ,roc 커브 , auc값 추출
print(report)
precision recall f1-score support
class 0 0.88 0.69 0.77 1175
class 1 0.76 0.91 0.83 1263
accuracy 0.80 2438
macro avg 0.82 0.80 0.80 2438
weighted avg 0.82 0.80 0.80 2438
plt.show()
print('base line: ROC AUC=%.3f' % (ns_auc))
print('pred: ROC AUC=%.3f' % (lr_auc))
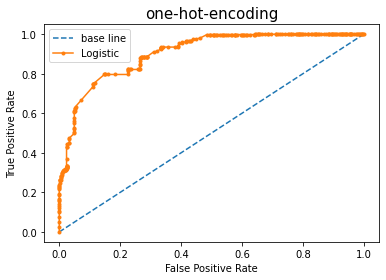
base line: ROC AUC=0.500
pred: ROC AUC=0.905